
 17612442707 17612442707
17612442707 17612442707 
如果有一个特别大的访问量,到数据库上,怎么做优化?
1 SQL 语句的优化处理
1.1 通过慢查询确认执行效率低下的 SQL 语句,进行拆解和索引的控制
1.2 使用索引
建立索引可以使查询速度得到提升,我们首先应该考虑在where及order by,group by涉及的列上建立索引。
1.3 SQL 的 Explain 通过图形化或基于文本的方式详细说明了 SQL 语句的每个部分是如何执行以及何时执行的,以及执行效果。通过对选择更好的索引列,或者对耗时久的SQL语句进行优化达到对查询速度的优化。
1.4 任何地方都不要使用SELECT * FROM语句。
1.5 不要在索引列做运算或者使用函数
1.6 查询尽可能使用limit来减少返回的行数
1.7 使用查询缓存,并将尽量多的内存分配给MYSQL做缓存
1.8 永远为每张表设置一个ID ,并作为主键
1.9 使用 ENUM 而不是 VARCHAR
1.10 从 PROCEDURE ANALYSE() 取得建议,PROCEDURE ANALYSE() 会让 MySQL 帮你去分析你的字段和其实际的数据,并会给你一些有用的建议.
1.11 尽可能的使用 NOT NULL
2 主从复制,读写分离,负载均衡
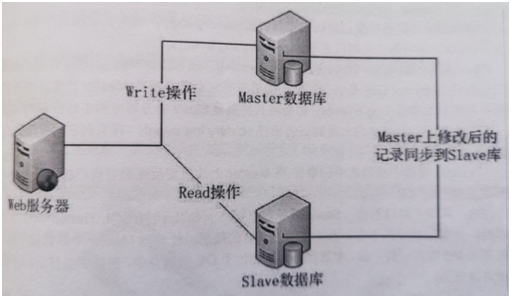
目前,大部分的主流关系型数据库都提供了主从复制的功能,通过配置两台(或多台)数据库的主从关系,可以将一台数据库服务器的数据更新同步到另一台服务器上。网站可以利用数据库的这一功能,实现数据库的读写分离,从而改善数据库的负载压力。一个系统的读操作远远多于其写操作,因此写操作发向master,读操作发向slaves进行操作(简单的轮循算法来决定使用哪个slave)。
利用数据库的读写分离,web服务器在写数据的时候,访问著数据库(Master),主数据库通过主从复制机制将数据更新同步到从数据库(Slave),这样web服务器读数据的时候,就可以通过从数据库获得数据。这一方案使得在大量读操作的web应用可以轻松地读取数据,而主数据库也只会承受少量的写入操作,还可以实现数据热备份,可谓是一举两得的方案。
l 复制的基本原则
MySQL复制是异步的且串行化的;
每个Slave只有一个Master;
每个Slave只有一个唯一的服务器ID;
每个Master可以有多个Slave;
l 一主一从常见配置:
MySQL版本一致且后台以服务运行;
主从都配置在[mysqld]结点下,都是小写,主机修改my.ini配置文件,从机修改my.cnf配置文件,因修改过配置文件,请主机+从机都重启后台MySQL服务;
主机从机都关闭防火墙;
在Windows主机上建立账户并授权slave;
在Linux从机上配置需要复制的主机;
主机新建库,新建表,insert记录,从机复制;
通过stop slave 停止从机复制;
l 主从复制的原理:
影响MySQL-A数据库的操作,在数据库执行后,都会写入本地的日志系统A中。假设,实时的将变化了的日志系统中的数据库事件操作,通过网络发给MySQL-B。MySQL-B收到后,写入本地日志系统B,然后一条条地将数据库事件在数据库中完成。那么MySQL-A的变化,MySQL-B也会变化,这样就是所谓的MySQL的复制。
在上面的模型中,MySQL-A就是主服务器,即master,MySQL-B就是从服务器,即slave。
日志系统A,其实它是MySQL的日志类型的二进制日志,也就是专门用来保存修改数据库的所有动作,即bin log。【注意MySQL会在执行语句之后,释放锁之前,写入二进制日志,确保事务安全。】
日志系统B,并不是二进制日志,由于它是从MySQL-A的二进制日志复制过来的,并不是自己的数据库变化产生的,有点接力的感觉,称为中继日志,即relay log。
可以发现,通过上面的机制,可以保证MySQL-A和MySQL-B的数据库数据一致,但是时间上肯定有延迟,即MySQL-B的数据是滞后的。
简化版:
l MySQL主(称master)从(称slave)复制的原理:
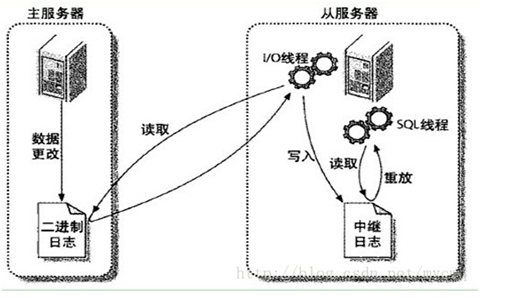
1.master将数据改变记录到二进制日志(binary log)中,也即是配置文件log-bin指定的文件(这些记录叫做二进制日志事件,binary log events)
PS:从图中可以看出,Slave服务器中有一个I/O线程(I/O Thread)在不停地监听Master的二进制日志(binary log)是否有更新:如果没有,它会睡眠等待Master产生新的日志事件;如果有新的日志事件(log events),则会将其拷贝至Slave服务器中的中继日志(relay log)。
2.slave将master的二进制日志事件(binary log events)拷贝到它的中继日志(relay log)。
3.slave重做中继日志中的事件,将Master上的改变反映到它自己的数据库中。所以两端的数据是完全一样的。
PS:从图中可以看出,Slave服务器有一个SQL线程(SQL Thread)从中继日志读取事件,并重做其中的事件,从而更新Slave的数据,使其与Master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。
l 主从复制的几种方式:
1.同步复制
主服务器在将更新的数据写入它的二进制日志(binlog)文件中后,必须等待验证所有的从服务器的更新数据是否已经复制到其中,之后才可以自由处理其他进入的事务处理请求。
2.异步复制
主服务器在将更新的数据写入它的二进制日志(binlog)文件中后,无需等待验证更新数据是否复制到从服务器中,就可以自由处理其他进入的事务处理请求。
3.半异步复制
主服务器在将更新的数据写入它的二进制日志(binlog)文件中后,只需等待验证其中一台从服务器的更新数据是否已经复制到其中,就可以自由处理其他进入的事务处理请求,其他的从服务器不用管。
3 数据库分表,分区,分库
通过分表可以提高表的访问效率。有两种拆分方法:
垂直拆分
在主键和一些列放在一个表中,然后把主键和另外的列放在另一个表中。如果一个表中某些列常用,而另外一些不常用,则可以采用垂直拆分。
水平拆分
根据一列或者多列数据的值把数据行放到两个独立的表中。
分区
分区就是把一张表的数据分成多个区块,这些区块可以在一个磁盘上,也可以在不同的磁盘上,分区后,表面上还是一张表,但是数据散列在多个位置,这样一来,多块硬盘同时处理不同的请求,从而提高磁盘I/O读写性能。实现比较简单,包括水平分区和垂直分区。
分库
分库是根据业务不同把相关的表切分到不同的数据库中,比如web、bbs、blog等库。
分库解决的是数据库端 并发量的问题。分库和分表并不一定两个都要上,比如数据量很大,但是访问的用户很少,我们就可以只使用分表不使用分库。如果数据量只有1万,而访问用户有一千,那就只使用分库。
分库分表最难解决的问题是统计,还有跨表的连接(比如这个表的订单在另外一张表),解决这个的方法就是使用中间件,比如大名鼎鼎的MyCat,用它来做路由,管理整个分库分表,乃至跨库跨表的连接
5 使用缓存技术如redis
上一篇: 求职面试中常见的问题---如何自我介绍
下一篇: 关于Redis缓存的Q&A

客服微信

公众号
扫描上方二维码 了解更多信息
现在报名即可享受多重福利

