
 17612442707 17612442707
17612442707 17612442707 
聚集索引和非聚集索引区别?

聚合索引(clustered index):
聚集索引表记录的排列顺序和索引的排列顺序一致,所以查询效率快,只要找到第一个索引值记录,其余就连续性的记录在物理也一样连续存放。聚集索引对应的缺点就是修改慢,因为为了保证表中记录的物理和索引顺序一致,在记录插入的时候,会对数据页重新排序。聚集索引类似于新华字典中用拼音去查找汉字,拼音检索表于书记顺序都是按照 a~z 排列的,就像相同的逻辑顺序于物理顺序一样,当你需要查找 a,ai 两个读音的字,或是想一次寻找多个傻(sha)的同音字时,也许向后翻几页,或紧接着下一行就得到结果了。
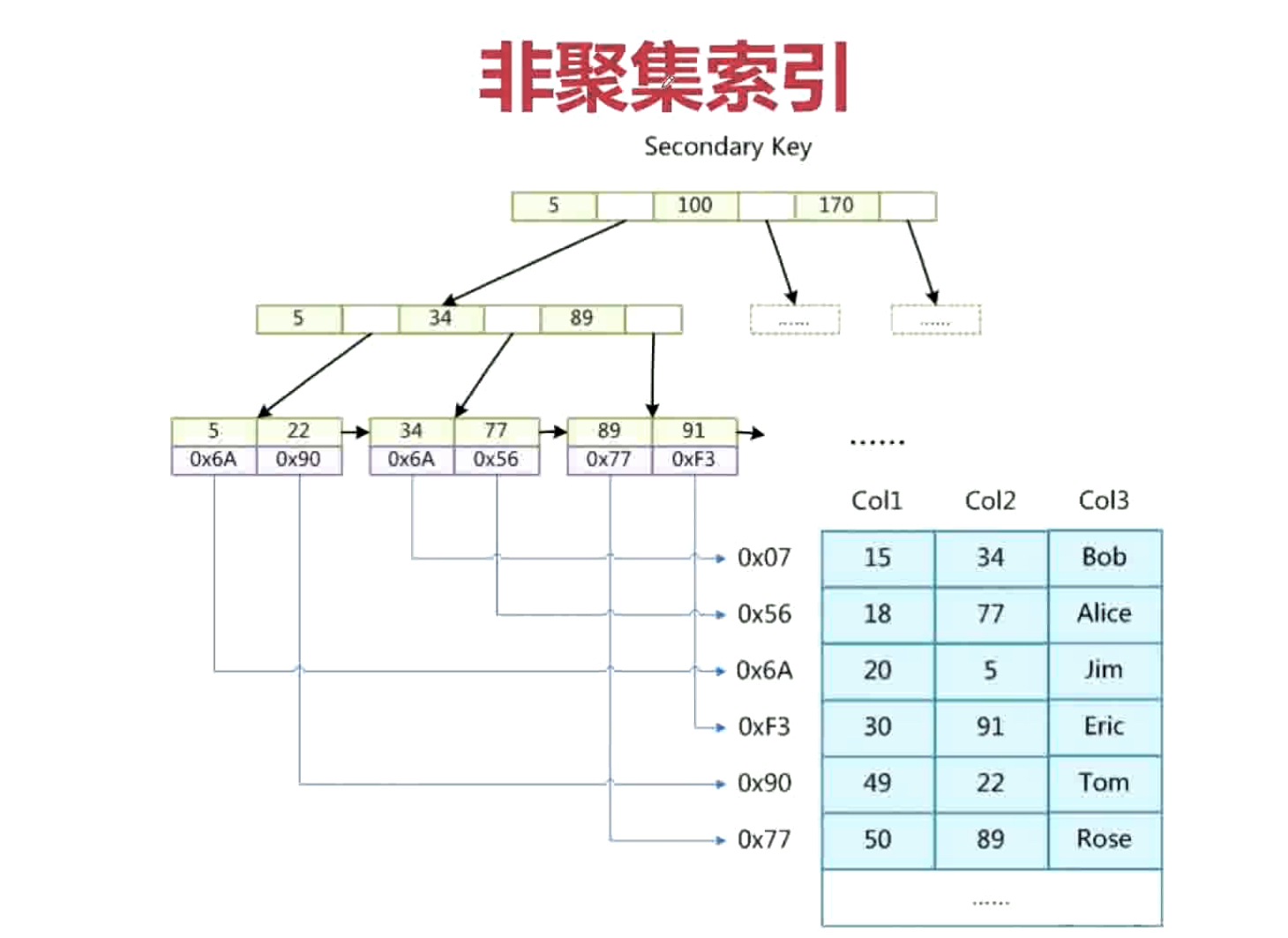
非聚合索引(nonclustered index):
非聚集索引指定了表中记录的逻辑顺序,但是记录的物理和索引不一定一致,两种索引 都采用 B+树结构,非聚集索引的叶子层并不和实际数据页相重叠,而采用叶子层包含一个指向表中的记录在数据页中的指针方式。非聚集索引层次多,不会造成数据重排。非聚集索引类似在新华字典上通过偏旁部首来查询汉字,检索表也许是按照横、竖、撇来排列的,但是由于正文中是 a~z 的拼音顺序,所以就类似于逻辑地址于物理地址的不对应。同时适用的情况就在于分组,大数目的不同值,频繁更新的列中,这些情况即不适合聚集索引。
根本区别:
聚集索引和非聚集索引的根本区别是表记录的排列顺序和与索引的排列顺序是否一致。
上一篇: 改变需要勇气
下一篇: Java线程池(一)

客服微信

公众号
扫描上方二维码 了解更多信息
现在报名即可享受多重福利

